
Services
The assessment of similarity vectors of fingerprint and UMLS in adverse drug reaction prediction
Identifying and controlling adverse drug reactions is a complex problem in the pharmacological field. Despite the studies done in different laboratory stages, some adverse drug reactions are recognized after being released, such as Rosiglitazone. Due to such experiences, pharmacists are now more interested in using computational methods to predict adverse drug reactions.
In computational methods, finding and representing appropriate drug and adverse reaction features are one of the most critical challenges. Here, we assess fingerprint and target as drug features; and phenotype and unified medical language system as adverse reaction features to predict adverse drug reaction. Meanwhile, we show that drug and adverse reaction features represented by similarity vectors can improve adverse drug prediction.
The main goal of this paper is to analyze drug features and adverse reaction features in drug-adverse reaction association prediction.
Meanwhile, we show that the similarity vector as a feature representation improves this result of prediction.
In this regard, we propose four frameworks.
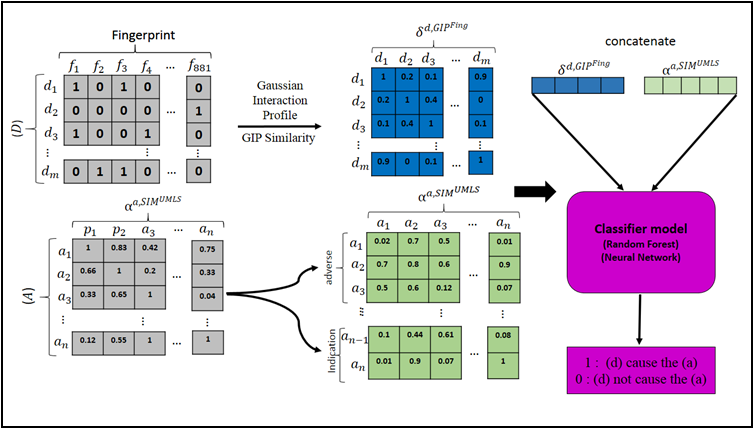
Two frameworks are based on random forest classification and neural networks as machine learning methods called F_RF and F_NN, respectively ( figure 1).
The rest of them improve two state-of-arts matrix factorization models named CS and TMF by considering target as a drug feature and phenotype as an adverse reaction feature. However, machine learning frameworks with fewer drug and adverse reaction features are more accurate than matrix factorization frameworks. In addition, the F_RF framework performs significantly better than F_NN with ACC = %89.15, AUC = %96.14 and AUPRC = %92.9. Next, we contrast F_RF with some well-known models designed based on similarity vectors of drug and adverse reaction features. Unlike other methods, we do not remove rare reactions from the data set in our frameworks.
Downloads
- Machine_learning_models.zip (259 MB).
- Matrix_factorization_models.zip (78 MB).
- readme.txt.
